
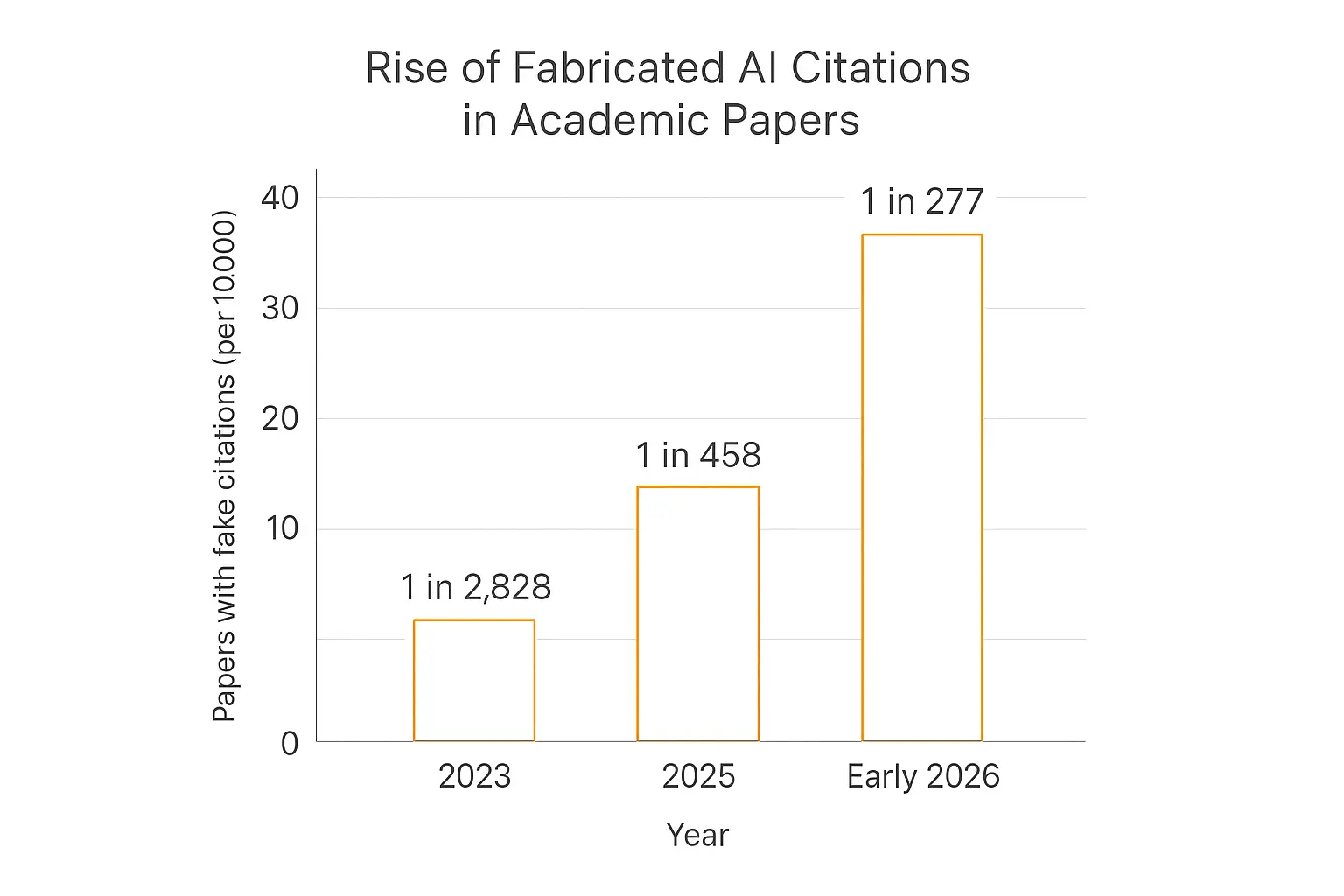
Here's a number that should make anyone using AI for research pause: in early 2026, roughly 1 in every 277 new academic papers contained at least one fabricated citation, according to a study covered by STAT News. Three years earlier, it was 1 in 2,828.
That's a tenfold increase. And these are professional researchers — people whose careers depend on getting references right.
The culprit isn't laziness. It's that AI tools confidently invent sources, and most people don't catch it. Researchers estimate around 146,900 hallucinated citations are now sitting in papers across arXiv, bioRxiv, SSRN, and PubMed Central.
So when I set out to build an AI research agent for my own workflow — something that could dig into a topic and hand me a summary I could actually trust — citations weren't a nice-to-have. They were the entire point.
In this guide, I'll walk through exactly how to build an AI research agent that cites real, checkable sources. No code required. We'll cover why AI invents references in the first place, the architecture that prevents it, a step-by-step build, and how to test the thing before you trust it.
What Is an AI Research Agent, Exactly?
An AI research agent is an AI system that takes a question, breaks it into research steps, gathers information from real sources, and synthesizes what it finds into a structured answer — with references showing where each claim came from.
That's different from asking ChatGPT a question. A chatbot answers from its training data, which is frozen in time and stored as statistical patterns, not documents.
A research agent actively goes and looks things up. The pipeline looks like this:
- Plan: Break the question into sub-questions worth investigating.
- Search: Run live queries against the web, databases, or a document library.
- Read: Pull the actual content of the sources it finds.
- Extract: Identify the specific facts, numbers, and quotes that answer the question.
- Verify: Check that each claim actually appears in the source it's attributed to.
- Cite & write: Compose the answer with a link attached to every claim.
Once you see research agents as this pipeline, you can predict exactly where they fail — and design around it. (If you want the broader primer first, I wrote a full explainer on what AI agents are and how they differ from chatbots.)
The category has exploded. OpenAI's Deep Research runs multi-step autonomous research loops, Google DeepMind announced Deep Research Max — an autonomous agent that produces "professional-grade, fully cited reports" — and Anthropic published the engineering behind Claude's multi-agent research system, where a lead agent spawns parallel sub-agents to search different angles of a question.
But here's the thing: even the flagship tools get citations wrong at a meaningful rate. Which brings us to the uncomfortable part.
Why Most AI Tools Invent Their Sources
Large language models don't store facts. They store patterns of how words follow other words.
When you ask a plain LLM for a citation, it generates something that looks like a citation: a plausible author, a plausible year, a journal that publishes that kind of work. The format is perfect. The reference is fiction.
This isn't an occasional glitch. A cross-model audit of reference fabrication benchmarked 13 LLMs across 40 research domains and found citation hallucination rates ranging from 14% all the way to 95% depending on the model and domain. In medical systematic reviews, studies have measured fabricated citation rates from 28.6% for GPT-4 up to 91.4% for older models.
Even purpose-built research agents aren't immune. A 2026 study on reference hallucinations in commercial deep research agents measured citation accuracy ranging from 78% for OpenAI Deep Research to 94% for Claude with search. Better — but a 6-22% error rate is still a real problem if you're making business decisions on the output.
Researchers distinguish two distinct failure modes:
- Citation hallucination: The reference itself doesn't exist. Fake DOI, fake paper, fake URL.
- Statement hallucination: The reference is real, but it doesn't say what the AI claims it says.
The second one is sneakier. The link works. The source is real. You click it, skim it, and assume the claim is in there somewhere. Often it isn't.
And humans are not the safety net we think we are. One researcher survey found a striking verification gap: 87% of researchers claim they always verify AI-generated citations — yet 42% admit to copy-pasting reference data without checking it.
The lesson for anyone building an AI research agent: you cannot prompt your way out of hallucination alone. You need architecture.
The Grounding Stack: How an AI Research Agent Keeps Citations Real
Every research agent that reliably cites its sources — whether it's Perplexity, Elicit, or one you build yourself — follows the same core principle:
The model is never allowed to answer from memory. It answers from documents it just retrieved.
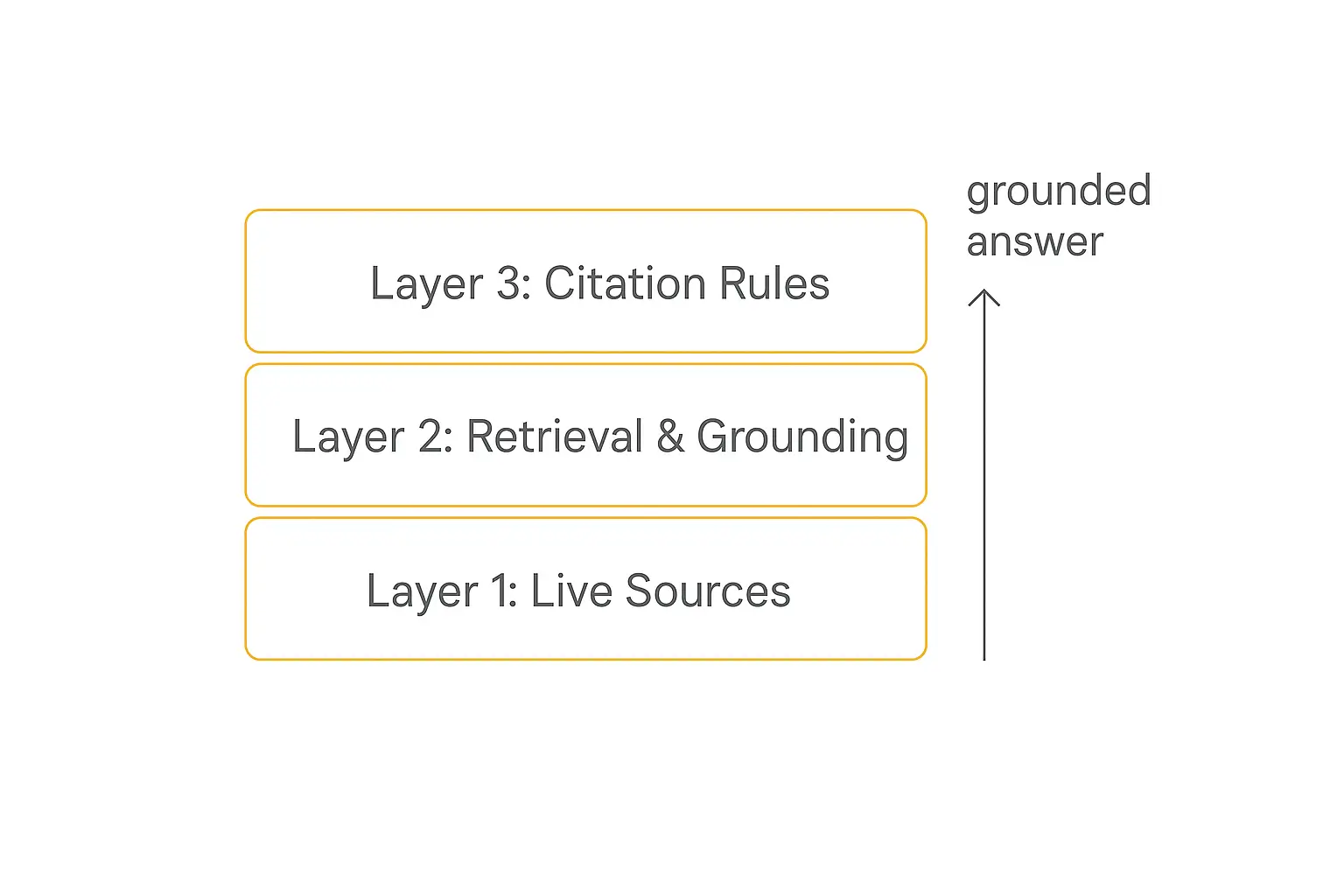
This is called grounding, and it works as a three-layer stack:
Layer 1: Live sources
The foundation is access to real, current information. That means web search, curated document libraries, academic databases, or structured data feeds — not training data frozen months or years ago.
This is why Perplexity was built around the idea of never answering without a source, and why Elicit connects directly to a corpus of 125+ million academic papers rather than relying on what the model "remembers."
Layer 2: Retrieval and grounding
The middle layer fetches the specific passages relevant to the question and places them in the model's context window at answer time.
This is retrieval-augmented generation (RAG), and it changes the failure mode completely. The model isn't recalling a paper from training — it's reading a document you handed it ten seconds ago. It can still misread, but it can't invent the document.
Layer 3: Generation with citation rules
The top layer is instruction: the model must attach a source to every factual claim, must quote rather than paraphrase when stakes are high, and must say "I couldn't verify this" instead of filling gaps with plausible fiction.
Prompting alone won't save you — but prompting on top of grounding is what separates a research agent from an expensive fiction generator.
Now let's build one.
How to Build an AI Research Agent Without Writing Code (Step by Step)
I built mine on Pickaxe because it gives me the three grounding layers without code: a knowledge base for documents, Actions for live web search and APIs, and full control over the agent's instructions. The same principles apply on any platform, so treat this as a blueprint.
Step 1: Define the research job narrowly
"Research anything" agents cite worse than focused ones. The narrower the domain, the easier it is to point the agent at trustworthy sources and write rules it can actually follow.
Good research-agent jobs look like:
- Competitor intelligence: "Summarize what changed on our competitors' pricing pages and changelogs, with links."
- Market research briefs: "Pull recent industry stats on X with a source for every number."
- Literature scans: "Find what published studies say about Y, quoting the relevant passages."
- Policy and compliance checks: "What do the actual regulations say about Z? Cite the section."
Write down the question types, the sources you trust for them, and what an ideal cited answer looks like. That's your spec.
Step 2: Write instructions that make citations non-negotiable
In Pickaxe's Agent Builder, the Prompt tab holds your agent's role instructions. This is where citation behavior is defined — explicitly, not implied.
Here's a condensed version of the citation rules I use:
You are a research assistant. Your defining trait: you never state
a fact you cannot point to a source for.
CITATION RULES (non-negotiable):
1. Every factual claim gets a source link in the same paragraph.
2. Only cite sources you have actually retrieved in this conversation —
from web search results or the knowledge base. Never cite from memory.
3. For statistics and direct quotes, include the exact figure or quote
as it appears in the source.
4. If you cannot find a source, write: "I could not verify this"
— never fill the gap with a plausible guess.
5. If two sources conflict, present both and say they conflict.
6. End every answer with a "Sources" list: title, publisher, URL, and
the date you accessed it.
NEVER invent, approximate, or reconstruct a URL, DOI, author name,
or publication date. A missing citation is acceptable. A fake one is not.Two details matter more than people expect. Rule 2 is the load-bearing one — it ties citations to retrieval, which is the whole grounding principle. And the "I could not verify this" escape hatch gives the model a legal move other than inventing something; without it, the model fills gaps because it has no permitted alternative.
Pickaxe also has a Model Reminder — an instruction prepended to every single user message. I put the short version there: "Cite a retrieved source for every claim. Never cite from memory." Long conversations erode instructions; the reminder re-anchors the rule on every turn.
Step 3: Ground it in a knowledge base
For any domain where you have trusted documents — industry reports, internal data, regulations, past research — upload them to the agent's Knowledge Base.
Pickaxe accepts PDFs, Word docs, text, CSVs, URLs, and even YouTube content, and breaks everything into searchable chunks the agent retrieves at answer time. Add a context instruction to each source telling the agent what it is and when to use it (e.g., "2026 industry benchmark report — primary source for market-size figures").
Sources added as URLs refresh daily, which quietly solves the staleness problem for things like pricing pages and changelogs. I covered the mechanics in my guide to uploading documents into an agent's knowledge base.
One rule of thumb: curate hard. Ten authoritative documents beat a hundred mediocre ones — retrieval quality degrades when the library is full of near-duplicates and marketing fluff.
Step 4: Connect live search with Actions
The knowledge base covers what you already have. For everything else, the agent needs to search the live web — and this is what Actions are for.
In Pickaxe, an Action connects your agent to an external tool or API. For a research agent, the essential one is web search; depending on your domain, you might add a news API, a financial data source, or a connection to your CRM. I walked through the setup in my Actions walkthrough.
Be explicit about the trigger in both the role prompt and the Action's own trigger description: "When the user asks about anything not covered by the knowledge base, or anything time-sensitive, run a web search before answering."
Keep it lean — Pickaxe recommends no more than 4 Actions per agent, and research agents genuinely don't need more. One search Action plus one or two domain data sources covers nearly every use case.
Step 5: Force a citation-first output format
Models follow structure more reliably than abstract rules, so give the output a fixed shape. Mine looks like this:
- Answer summary — 2-3 sentences, the headline finding.
- Key findings — each finding as a bullet, with its source linked inline.
- Conflicting evidence — anything sources disagree on (often the most valuable section).
- What I couldn't verify — explicit gaps, stated as gaps.
- Sources — full list: title, publisher, URL, access date.
That fourth section does psychological work on the model. When "unverified" is a designated place in the template, claims that lack sources get routed there — instead of being dressed up with a fabricated reference to satisfy the format.
Step 6: Add a self-check pass
Before the agent sends an answer, make it audit itself. Add this to the instructions:
Before responding, review your draft:
- Does every factual claim have a source retrieved this conversation?
- Does every URL in your Sources list come verbatim from a search
result or knowledge base document — not from memory?
- Are quotes exact?
If any check fails, fix the draft before sending: find the source,
move the claim to "What I couldn't verify," or cut it.A single self-check pass won't catch everything, but it measurably cuts the casual failures — the paraphrase that drifted from the source, the URL the model "remembered" instead of retrieved.
Step 7: Try to break it
Now test like an adversary, not a fan. In Pickaxe's Preview tab, hit the agent with questions designed to induce hallucination:
- Ask about something that doesn't exist. "What did the 2025 Henderson Report say about AI adoption?" (There is no Henderson Report.) A grounded agent says it can't find it. An ungrounded one summarizes it for you.
- Ask for precision it can't have. Exact figures from paywalled or obscure sources. The correct answer is "I couldn't verify this."
- Ask leading questions with false premises. "Why did Company X exit the European market?" when they didn't.
- Click every link. Then check the claim actually appears in the source — remember, statement hallucination survives a working URL.
I keep a small set of these traps and re-run them whenever I change the prompt, the model, or the knowledge base. My full testing methodology is in how to test and debug your AI agent before deploying it.
Build a research agent that shows its work
Knowledge base, live web search via Actions, and full prompt control — no code required.
Step 8: Deploy where the research happens
Once it passes your trap tests, ship it where you (or your team, or your clients) actually work. Pickaxe agents deploy as an embedded widget on your site, a standalone page, a Slack bot, a WhatsApp bot, or inside a branded portal alongside your other agents.
For client work, the portal route is worth a serious look — agencies package research agents with their other deliverables and bill for them. If that's your angle, the numbers are in my breakdown of how to measure AI agent ROI.
Worked Example: A Competitor-Intel Agent That Cites Everything
Theory is nice; here's an actual build. This is the competitor-intelligence agent I run, end to end.
The job: Answer questions like "What changed in Competitor X's pricing this quarter?" and "How are they positioning their new agent feature?" — with a link for every claim, because these answers go into strategy docs other people act on.
The knowledge base: About fifteen sources, all added as URLs so they refresh daily:
- Each competitor's pricing page, changelog, and blog.
- Two industry analyst reports we have rights to (PDFs).
- Our own positioning doc, with a context instruction: "Internal reference only — never cite this as evidence about competitors."
The Actions: Exactly two. A web search Action for anything outside the library — funding news, reviews, social chatter — and a Google Sheets Action that logs every research request and the sources used, which gives me an audit trail for free.
The prompt: The citation rules from Step 2, plus three domain-specific lines:
- Pricing claims must cite the competitor's own pricing page,
retrieved this conversation — never a third-party roundup.
- Anything from a review site or social post must be labeled
"anecdotal" in the answer.
- If a claim is older than 90 days, include its date inline.That first line exists because third-party "pricing comparison" articles are reliably stale — the agent kept citing a roundup that was eight months out of date. Forcing primary sources fixed it in one line.
What the output looks like: Ask it "Did Competitor X raise prices this year?" and you get: a two-sentence answer, the specific plan changes as bullets each linked to the live pricing page, a note that one review-site claim about grandfathered accounts is anecdotal, and a dated source list. Total build time was an afternoon. The trap-question suite took longer than the agent.
What it gets wrong: Honestly — recency edge cases. A price change from yesterday sometimes hasn't hit the knowledge base refresh yet, so the web search Action catches it, but occasionally with a cache-stale snippet. The "include dates inline" rule means I can see when that happens. That's the point: the agent's failures are visible instead of silent.
Choosing the Model: It Matters More Than You'd Think
Citation discipline varies sharply by model. That reference-hallucination study found a 16-point spread in citation accuracy across commercial systems — and the academic audits found spreads from 14% to 95% across raw models.
A few practical guidelines from my own builds:
- Use a current frontier model for the research itself. Stronger models follow citation rules dramatically better and are less prone to filling gaps with fiction.
- Don't cheap out on synthesis. Budget models are fine for formatting and routing, but the step that turns sources into claims is exactly where hallucination happens.
- Re-test when you switch. Citation behavior is a per-model property. Your trap-question suite is the regression test.
Pickaxe is model-agnostic — you pick from the full range of OpenAI, Anthropic, Google, and open-source models and can switch at any time, which makes the re-test loop painless: change model, run traps, compare.
Build vs Buy: The AI Research Agent Landscape
Building isn't always the answer. Here's how I'd map the options:
| Tool | Best for | Citation approach | Limitation |
|---|---|---|---|
| Perplexity | Fast general research | Inline sources on every answer, by default | General-purpose; no custom knowledge base or branding |
| Elicit | Academic literature review | Grounded in 125M+ papers, exports to reference managers | Academic corpus only — not built for business research |
| Consensus | "What does the science say?" | Claims tied to specific published studies | Same academic scope limitation |
| OpenAI Deep Research | Long autonomous reports | Numbered references in structured reports | 78% measured citation accuracy; slow; per-task cost |
| Gemini Deep Research | Reports over web + your docs | Fully cited reports | Tied to the Google ecosystem |
| Claude Research | Multi-angle parallel research | Multi-agent search with checkable citations | Lives inside Claude, not your product |
| Build your own (Pickaxe) | Domain-specific, client-facing, or monetized research agents | You control grounding, sources, and citation rules | You own the testing and upkeep |
The pace here is fast: Elicit recently shipped citation filtering and direct export to reference managers, and OpenAI's deep research agent now reads entire GitHub repos and returns cited reports. The cited-research bar keeps rising — which is good news for everyone who reads the outputs.
The honest decision rule: if a generic tool answers your question, use the generic tool. Perplexity is excellent at what it does.
Build your own when you need your sources (internal docs, niche databases, curated libraries), your rules (output formats, compliance constraints, citation standards), or your distribution — embedding the agent in your product, deploying it to a client, or selling access to it. That last category is where no-code platforms earn their keep, and it's the gap none of the flagship tools address: OpenAI's agent writes reports for you; it doesn't become a product of yours.
Advanced Patterns: Multi-Agent Verification and Scheduled Research
Once the basic agent works, two patterns take it further.
The researcher-verifier pattern
The most effective anti-hallucination architecture I've used splits the job in two: one agent researches and drafts, a second agent — with instructions purely adversarial — checks every citation in the draft against the retrieved sources and flags anything that doesn't hold up.
This mirrors how Anthropic's own research system works: a lead agent orchestrating specialized sub-agents, because separating roles beats asking one agent to grade its own homework. In Pickaxe you build this as a waterfall: the primary agent routes its draft to the verifier via an agent-to-agent Action. My deep dive on multi-agent systems covers when this is worth the complexity — and when it's overkill.
Scheduled research digests
Research agents don't have to wait for questions. Connect one to an automation platform like Zapier, Make, or n8n via MCP and run it on a schedule: every Monday, scan the week's industry news and deliver a cited digest to Slack or email.
The citation rules matter even more here — nobody is in the loop to catch a fabricated source before the digest lands in an inbox. Trap-test the scheduled version just as hard.
Common Mistakes That Quietly Break Citations
I've watched a lot of people build research agents at this point. The same five mistakes account for most of the fabricated sources that slip through.
1. Adding citation rules but no retrieval
The most common one, and the most dangerous. An agent with no web search and no knowledge base cannot cite real sources — it has nothing to cite from. The rules just make its inventions look more professional. If you do only one thing from this guide, make it grounding.
2. Letting the knowledge base rot
A research agent grounded in stale documents confidently cites real sources that are no longer true. Use URL sources with auto-refresh where you can, and put a recurring reminder on the PDFs you can't.
3. Trusting a working link
Statement hallucination — real source, wrong claim — survives every link check. When you test, don't just click the URL; find the actual sentence in the source that supports the claim. This is the check the 42% of copy-paste researchers skip, and it's the one that matters.
4. Asking one agent to grade its own homework at scale
The self-check pass in Step 6 is real but modest. If your research agent's output feeds decisions with money attached, add the separate verifier agent. Self-review catches typos in reasoning; adversarial review catches motivated reasoning.
5. Skipping the re-test after "small" changes
A model switch, a new knowledge base document, a tweaked prompt — each one can shift citation behavior. The trap-question suite from Step 7 takes ten minutes to re-run. Treat it like a test suite: it runs on every change, not just the launch.
Most of these reduce to one habit: treat the agent's citations as claims to verify, not features to admire. The agents that earn trust are the ones whose builders kept trying to catch them lying.
Your research, your sources, your rules
Pickaxe agents ground every answer in the documents and live searches you choose — then deploy to your site, Slack, or a client portal.
FAQ: AI Research Agents and Citations
Can an AI research agent guarantee 100% accurate citations?
No — and be suspicious of anything that claims otherwise. Grounding plus citation rules plus a verifier pass gets you from "untrustworthy" to "spot-check level," the same trust you'd give a good junior analyst. The best measured systems still sit around 94% citation accuracy.
What's the difference between an AI research agent and deep research tools like OpenAI's?
Same pipeline, different ownership. Deep Research is a finished product running on OpenAI's sources and rules. Building your own means choosing the sources, the citation standard, the output format, and where it deploys — at the cost of doing the testing yourself.
Why does my agent still make up sources even though I told it not to?
Because instructions without retrieval don't work. If the agent has no web search or knowledge base, it physically has nothing real to cite — "cite your sources" just makes it format its fiction more convincingly. Grounding first, rules second.
Do I need RAG, or is web search enough?
For current-events research, web search alone works. Add a knowledge base when you have documents the web doesn't — internal reports, purchased research, niche archives — or when you want answers anchored to a vetted library instead of whatever ranks on Google.
How much does it cost to build an AI research agent?
On a no-code platform, it's a subscription rather than a development project — Pickaxe plans bundle model usage as credits, and you can check current tiers on the pricing page. Compare that to API-and-code routes where you're managing model bills, vector databases, and hosting separately.
The Real Lesson: Trust Is the Product
The research showing 1 in 277 papers now carry fabricated citations isn't really a story about careless researchers. It's a story about what happens when people use ungrounded AI for research at scale — the failure is silent, plausible, and compounding.
An AI research agent that cites its sources flips that. Every claim carries its receipt. Errors become checkable instead of invisible. The output isn't just an answer — it's an answer you can audit.
The recipe, one more time: narrow the job, ground every answer in retrieved sources, make citations structurally non-negotiable, give the model permission to say "I don't know," and test it like an adversary.
None of that requires code anymore. It requires deciding that "sounds right" isn't good enough — and about an afternoon of building.
If you want to try it, spin up an agent on Pickaxe, paste in the citation rules from Step 2, connect web search, and run the Henderson Report test. The first time your agent says "I couldn't find that source" instead of inventing one, you'll feel the difference.





