
Here's a thing that trips up almost everyone building their first AI agent: you have a great conversation with it, close the tab, come back an hour later, and it has no idea who you are. It greets you like a stranger. It re-asks the questions you already answered. It forgets the project you spent twenty minutes explaining.
That's not a bug. That's the default. Out of the box, most AI agents are amnesiacs — brilliant in the moment, blank the second the session ends.
AI agent memory is the layer that fixes this. It's the difference between an agent that feels like a goldfish and one that feels like a colleague who actually remembers your last meeting.
I've spent a lot of time digging into how memory actually works in modern agents — the short-term tricks, the long-term storage, the frameworks everyone's arguing about, and the places where the whole thing quietly falls apart. This guide is the honest version: what the different types of memory are, how retrieval really works under the hood, and — the part most articles skip — when you genuinely don't need any of it.
If you're still fuzzy on the basics, my guide to what AI agents are is a better starting point. This one assumes you know what an agent is and want to understand the thing that makes it feel persistent.
What Is AI Agent Memory?
AI agent memory is any mechanism that lets an agent retain and reuse information beyond a single model call. It's how an agent carries context across turns, sessions, and sometimes across months.
The confusion usually starts here: people assume the large language model is the memory. It isn't.
A model like Claude or GPT is stateless. Each request is processed fresh. The model doesn't "remember" your last message — the only reason a chatbot seems to follow a conversation is that the entire conversation history gets re-sent with every single request. The model is reading the whole transcript again, every time, as if for the first time.
That works fine for a short chat. It breaks the moment the conversation gets long, spans multiple sessions, or needs to recall something from last week. The transcript can't grow forever, and re-sending it isn't free.
So memory is the engineering you add around the model to decide what information to keep, where to keep it, and how to feed the right pieces back in at the right moment. Anthropic calls this broader discipline context engineering — "the art and science of filling the context window with just the right information for the next step."
That phrase comes straight from a now-famous take by Andrej Karpathy, former director of AI at Tesla, who argued we should call it context engineering rather than prompt engineering — because in any serious app, deciding what goes into the context window is the whole game. Memory is the part of that game that deals with time.
Short-Term vs. Long-Term Memory
The cleanest way to think about agent memory is to borrow the framing from your own brain: there's short-term memory (what you're holding in your head right now) and long-term memory (everything you've stored away and can recall later).
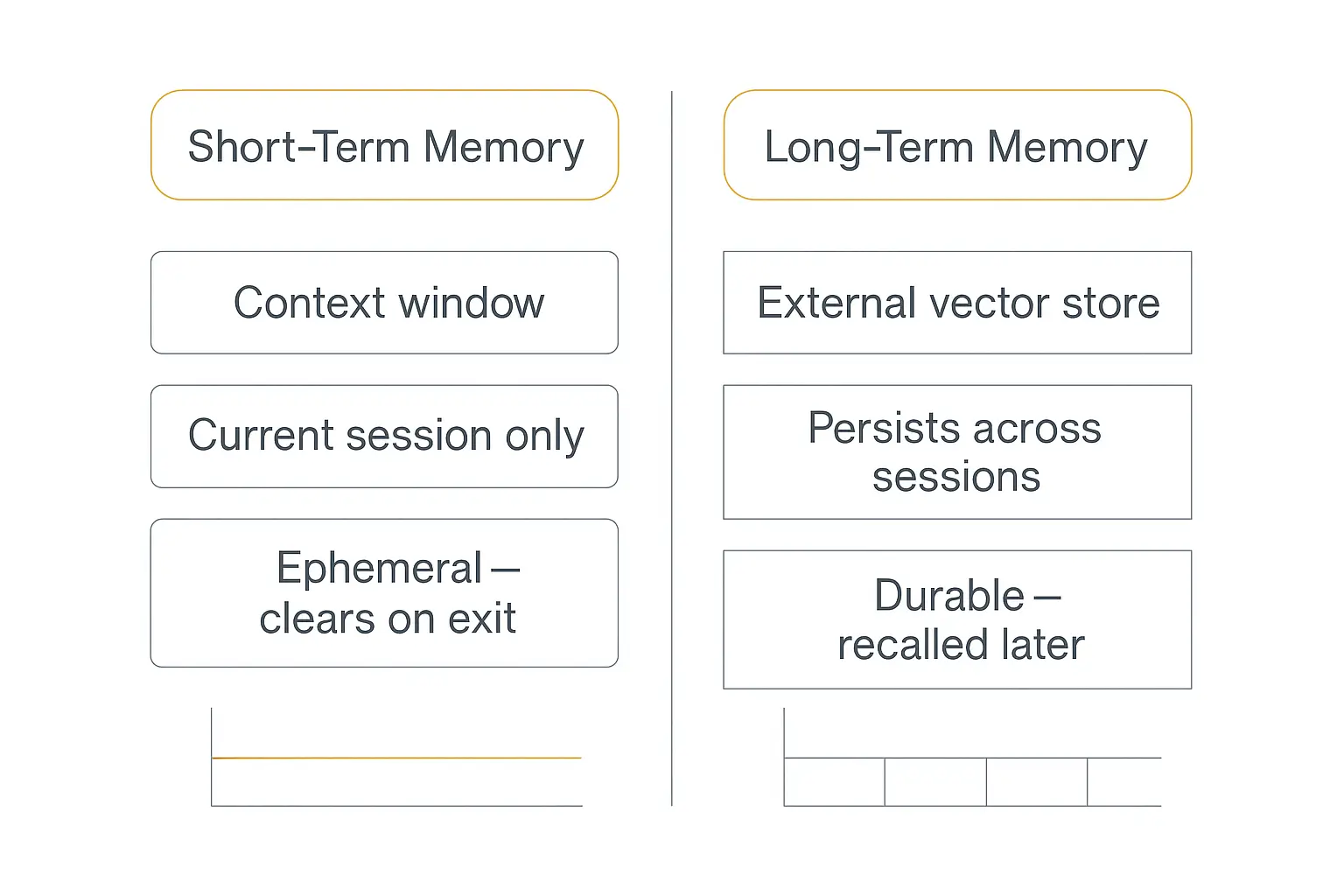
Short-term memory (the context window)
Short-term memory is the context window — the model's working RAM. It holds the system prompt, the recent back-and-forth, and any tool outputs for the current session.
In practice it's implemented in a few ways:
- Conversation buffer: keep the entire history and re-send it every turn. Simple, but it bloats fast.
- Buffer window: keep only the last N turns. Cheaper, but the agent forgets anything older.
- Running summary: compress older turns into a short summary and keep that instead of the raw text. The middle path most production systems use.
The defining trait of short-term memory is that it's ephemeral. When the session ends, it's gone — unless you deliberately persist it somewhere. Frameworks like LangGraph handle this with a "checkpointer" that saves the thread state so a conversation can be paused and resumed.
Long-term memory (the external store)
Long-term memory lives outside the model, in durable storage that survives sessions. This is where an agent keeps your preferences, your past projects, facts about your business — anything it should still know next month.
It almost always involves a vector database (for semantic search over past content) and sometimes a graph database (for tracking how entities relate over time). We'll get into how that retrieval actually works in a minute.
The key insight: long-term memory decouples what the agent knows from what it has to process. Instead of cramming everything into the context window every turn, you store it externally and pull back only the handful of relevant pieces when they're needed. That's cheaper and, it turns out, often more accurate.
The Three Types of Memory: Episodic, Semantic, and Procedural
Once you go past the short-term/long-term split, researchers borrow a more useful taxonomy from human cognitive science — originally from psychologist Endel Tulving's work on how human memory is organized. Modern agent frameworks lean on the same three categories.
| Type | What it stores | Agent example |
|---|---|---|
| Episodic | Specific past experiences — what happened, what the agent did, what resulted | "Last Tuesday this user asked for a refund and I escalated it to a human." |
| Semantic | Context-independent facts — preferences, profiles, domain knowledge | "This user prefers email over phone and works in healthcare." |
| Procedural | Knowing how — workflows, rules, tool-use patterns | "To process a refund: verify order, check policy window, then issue or escalate." |
Episodic memory is the agent's diary. It's a log of specific interactions with enough detail to recall not just what was said, but what was done and how it turned out.
Semantic memory is the agent's knowledge base. Stable facts that don't belong to any one event — who the user is, what your products cost, how your industry works. This is the type most people mean when they say they want their agent to "remember" things.
Procedural memory is the agent's muscle memory. It's the how-to: the workflows and decision rules. In most systems this lives in the system prompt or the code rather than a database, but the principle is the same — it's retained know-how.
The reason this matters: they feed each other. Patterns an agent sees over and over in episodic memory can be distilled into semantic facts. If a user corrects the agent three times the same way, that correction should graduate from "a thing that happened" to "a thing I now know." That generalization step is where good memory systems earn their keep.
How Retrieval-Augmented Memory Actually Works
So how does an agent reach into a store of thousands of past memories and pull out the three that matter for your current question? This is the part that feels like magic and is really just four steps.
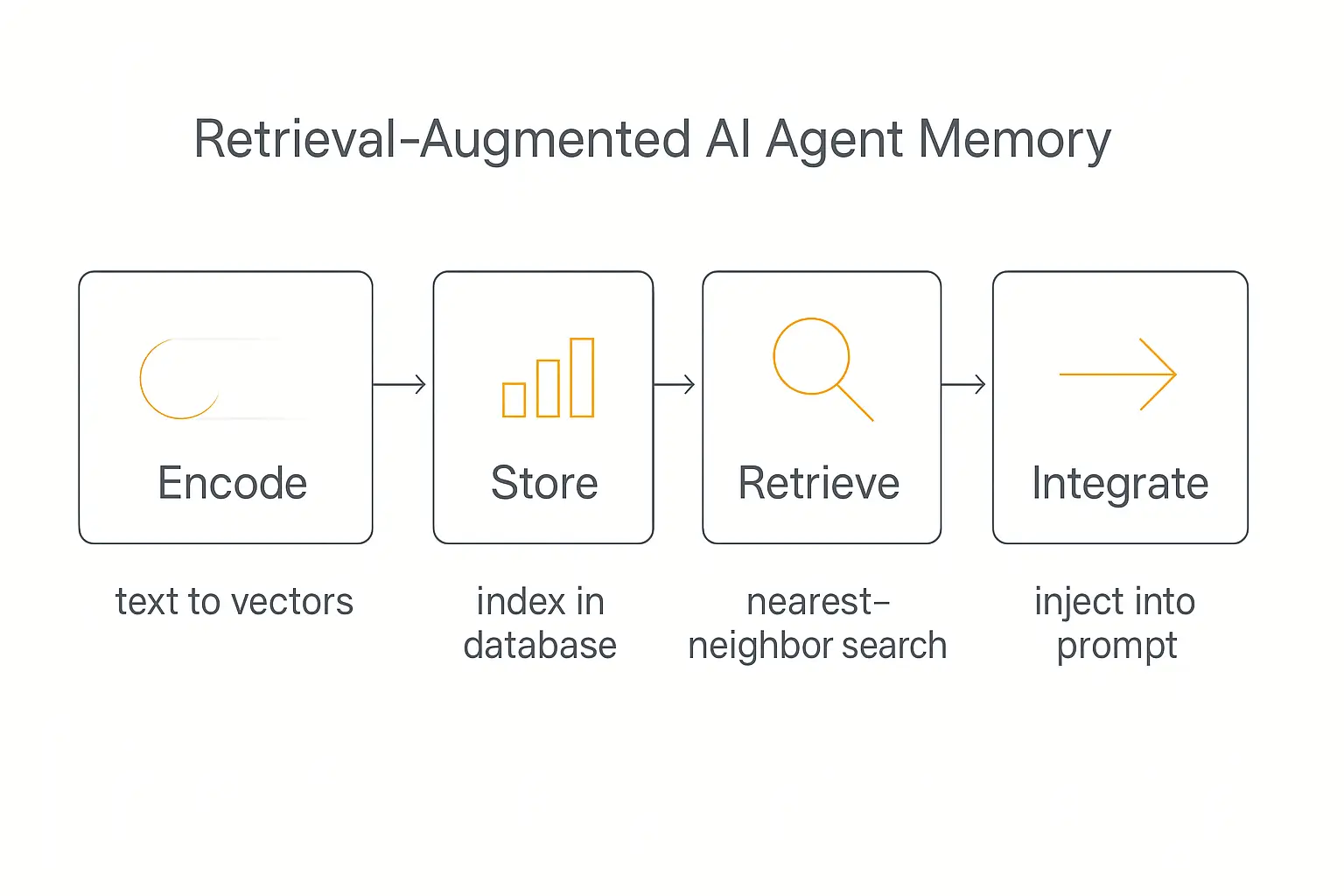
1. Encode. Text gets converted into an embedding — a long list of numbers (a vector) that captures its meaning. Two sentences that mean similar things end up with similar vectors, even if they share no words.
2. Store. Those vectors get indexed in a vector database so they can be searched quickly. Tools like Pinecone, Weaviate, and Chroma handle this, as does pgvector if you'd rather keep it in Postgres.
3. Retrieve. When a new message comes in, it gets encoded too, and the database finds the stored vectors closest to it — a nearest-neighbor search. Good systems then rerank the results and filter by metadata (date, user, topic) so you get the most relevant memories, not just the most superficially similar.
4. Integrate. The retrieved memories get injected into the prompt before the model runs, so the agent answers as if it remembered. This is the same machinery behind retrieval-augmented generation (RAG) — memory is essentially RAG pointed at the agent's own history instead of a document library.
Here's the design decision that separates good memory from bad: what you choose to write. Dumping raw conversation turns into the store creates noise — retrieval then drags back rambling, half-relevant text. The better approach, used by most modern memory layers, is to extract clean facts ("user's company has 12 employees") before storing, so retrieval pulls back signal instead of transcript.
Give your agent a memory without touching a vector database.
Pickaxe handles the storage, embeddings, and retrieval so you can focus on what your agent should know.
Hybrid Approaches and Memory Hierarchies
In the real world, nobody uses just one kind of memory. The interesting systems are hybrids that combine cheap-but-limited short-term context with rich-but-slower long-term storage.
The most influential model here came from a 2023 UC Berkeley paper called MemGPT: Towards LLMs as Operating Systems. Its big idea: treat the context window like a computer's RAM and treat external storage like disk, then let the agent page information in and out the way an operating system manages virtual memory.
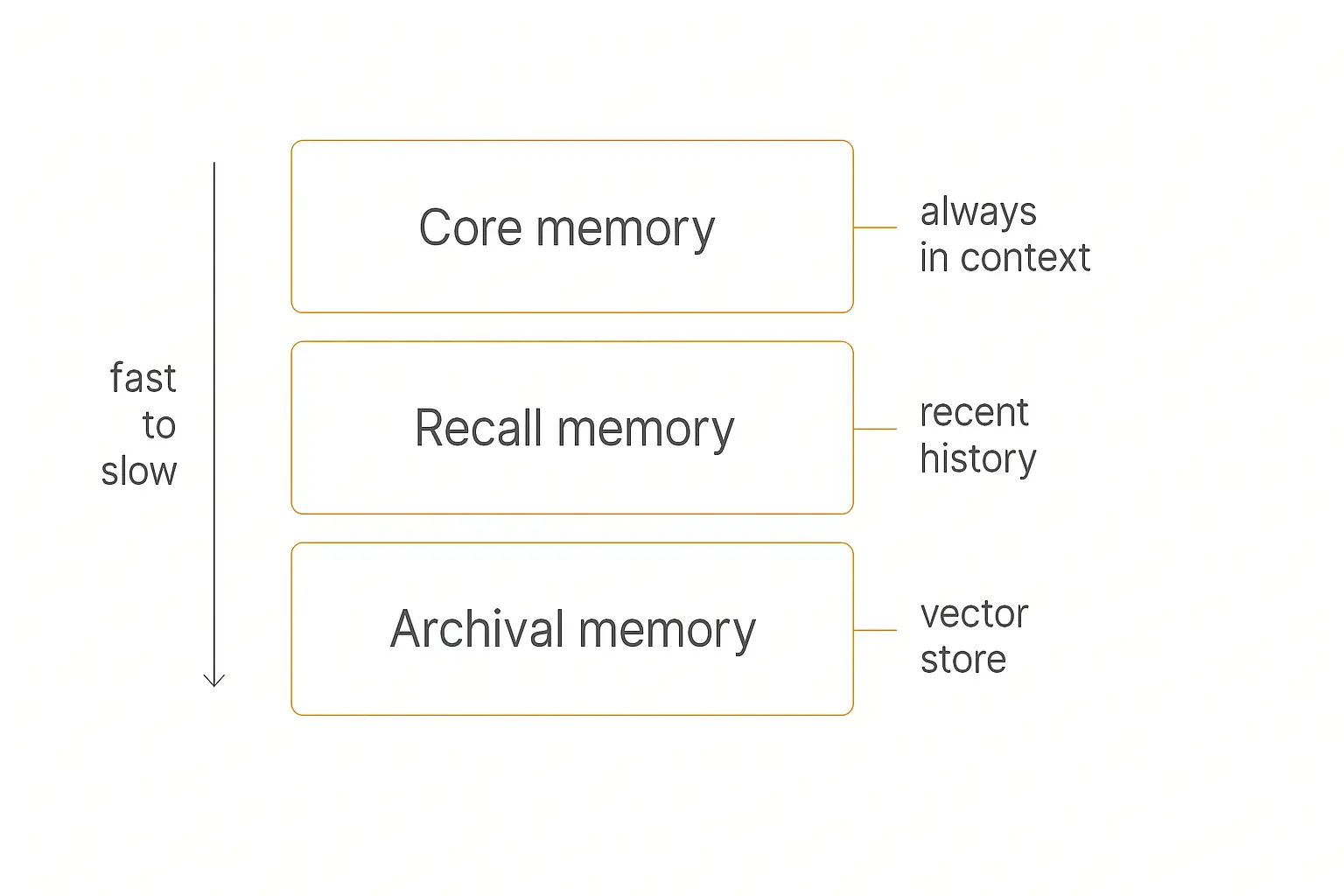
That gives you a tiered hierarchy:
- Core memory — always in the context window. The agent's essential facts, like RAM. Fast, but tiny.
- Recall memory — searchable recent history the agent can pull from on demand.
- Archival memory — the deep vector store, like cold storage on disk. Huge, but you have to go fetch it.
The agent decides what to promote into core memory and what to push down to archival, managing its own attention budget. MemGPT eventually became a company, Letta, which now builds agent runtimes around exactly this idea.
Beyond the OS metaphor, the other common hybrid pattern is summarization plus retrieval: keep a running summary of the conversation in context (cheap, always available) while offloading the full detail to a retrievable store. You get the gist for free and the specifics on request.
The AI Agent Memory Tools Landscape
The memory space got crowded fast in 2025 and 2026. Here's an honest map of the main players and what each is actually for.
| Tool | What it is | Best for |
|---|---|---|
| Letta (MemGPT) | An agent runtime built around tiered, self-managed memory | Developers who want memory baked into the agent itself |
| Mem0 | A memory layer you bolt onto an existing framework | Adding persistent memory to an agent you already built |
| Zep / Graphiti | Temporal knowledge-graph memory that tracks how facts change over time | Regulated industries and relationship-heavy data |
| LangMem / LangGraph | Memory primitives inside the LangChain ecosystem | Teams already building on LangGraph |
| Claude memory tool | A file-based memory the model reads and writes itself | Agents built directly on the Claude API |
Mem0 positions itself as the easy add-on. Its 2025 paper reports big wins — a 26% relative quality improvement over OpenAI's memory and over 90% token-cost savings on a long-conversation benchmark. Worth knowing those numbers are self-reported by the Mem0 team, so read them as a vendor claim, not a neutral result.
Zep takes the contrarian "stop using plain RAG for memory" stance, arguing that a temporal knowledge graph handles changing facts better than a flat vector store. Its open-source engine, Graphiti, has picked up serious traction on GitHub.
The big model providers have moved in too. OpenAI gave ChatGPT memory in 2024 and has since expanded it to reference all past chats. Anthropic shipped a memory tool for Claude in late 2025 that lets the model keep notes in a file directory it manages itself.
If you're choosing a foundation model to sit underneath any of this, my rundown of the best LLMs walks through the trade-offs. The memory layer and the model are separate decisions.
The Hard Parts Nobody Puts in the Demo
Memory demos always look magical. Production memory is where things get messy. Here are the failure modes I'd want you to know about before you build.
A bigger context window is not the same as memory
The tempting shortcut is "just use a model with a million-token context window and stuff everything in." It doesn't work as well as you'd hope.
Chroma ran a study they call context rot, testing 18 frontier models including GPT, Claude, and Gemini. The finding: model performance degrades as the input gets longer, even on simple tasks, well before the advertised context limit. A huge context window is a place to put tokens, not a guarantee the model will use them well. Selective retrieval beats brute-force stuffing.
Memory bloat and bad retrieval
Store everything and you get a junk drawer. Retrieval starts pulling back stale, irrelevant, or contradictory memories, and the agent's answers get worse, not better. This is why fact extraction, reranking, and metadata filtering aren't optional niceties — they're what keep the store from poisoning itself.
The cost of remembering everything
Re-sending a growing history every turn gets expensive fast — the cost scales with the square of the conversation length, because every new turn re-processes everything before it. This is the quiet economic reason long-term memory exists at all: it's almost always cheaper to store knowledge externally and retrieve a little than to carry everything in context forever.
Stale memory is worse than no memory
This one's genuinely unsolved. If your agent learned "the user is planning a trip to Japan" three months ago, when does that stop being true? The trip happened, or got cancelled, and now the agent keeps bringing up a thing that's no longer relevant. Knowing when to forget or update a fact is one of the open problems the whole field is still wrestling with.
Memory can leak into the wrong place
Developer Simon Willison documented a sharp example: ChatGPT pulled his location out of memory and unexpectedly injected it into an image it generated for an unrelated request. Personalization that bleeds into the wrong task isn't helpful — it's unsettling, and it erodes trust. Memory comes with real privacy and consent questions that don't have clean answers yet.
Do You Even Need Persistent Memory?
Here's the take you won't get from a company selling a memory product: a lot of agents don't need long-term memory at all.
If your agent does single-turn question answering, one-shot generation, or stateless tasks where each request stands alone, persistent memory adds cost and complexity for no benefit. A stateless agent is simpler, cheaper, more predictable, and easier to debug.
Memory earns its complexity in specific situations:
- Multi-session personalization — the agent should recognize returning users and adapt.
- Long-horizon tasks — work that spans days and can't fit in one context window.
- Learning from past interactions — the agent should get better at your specific needs over time.
For everything else, the honest answer is often a hybrid: a stateless core workflow with a small, deliberate slice of persistent memory bolted onto just the parts that need it. Statefulness is a cost. Spend it where it pays off, not everywhere by default. Before you reach for it, it's worth pressure-testing your agent — my guide on how to test and debug an AI agent covers how to tell whether memory is actually improving behavior or just adding noise.
How Pickaxe Handles Memory for No-Code Builders
Most of what I've described — vector databases, embeddings, reranking, tiered hierarchies — assumes you're writing code. The whole point of Pickaxe is that you don't have to.
When you build an agent on Pickaxe, the short-term conversation memory is handled for you within each chat. For long-term knowledge, you add a knowledge base — upload your documents, FAQs, product specs, or past content, and Pickaxe takes care of the embedding and retrieval behind the scenes. That's the encode-store-retrieve loop from earlier, minus the part where you stand up a vector database yourself.
You also get to choose the model underneath your agent, so you can match the brain to the job without rebuilding the memory layer each time.
The result is the same persistent-feeling agent the frameworks give developers — one that remembers your business and your customers — without the infrastructure project. If you're weighing whether to assemble this yourself or use a platform, my build vs. buy guide is a useful gut-check.
Build an agent that remembers your customers.
Upload your knowledge, pick your model, and deploy — no vector database required.
Frequently Asked Questions
What is AI agent memory in simple terms?
It's the system that lets an AI agent remember information beyond a single message — across a conversation and, with long-term memory, across sessions. Since the underlying model is stateless, memory is the engineering layer added around it to store and recall the right context at the right time.
What's the difference between short-term and long-term memory?
Short-term memory is the context window — the working space holding the current conversation, which disappears when the session ends. Long-term memory is durable external storage (usually a vector database) that persists facts and past interactions so the agent can recall them later.
What are episodic, semantic, and procedural memory?
Episodic memory stores specific past experiences ("what happened last Tuesday"). Semantic memory stores context-independent facts ("this user works in healthcare"). Procedural memory stores know-how — the workflows and rules for getting things done. Together they let an agent personalize, recall facts, and act consistently.
Is a bigger context window the same as having memory?
No. A large context window gives you more room to place tokens, but research on context rot shows models get less reliable as inputs grow, even below the advertised limit. Selective retrieval from a memory store usually beats stuffing everything into a long prompt.
What's the best AI agent memory framework?
It depends on your setup. Letta builds memory into the agent runtime, Mem0 is an easy add-on layer, Zep specializes in temporal knowledge graphs, and LangMem fits the LangChain ecosystem. If you don't want to manage any of it, a no-code platform like Pickaxe handles memory and retrieval for you.
Do all AI agents need long-term memory?
No. Stateless agents that handle single-turn or one-shot tasks are simpler and cheaper without it. Persistent memory pays off for multi-session personalization, long-horizon tasks, and agents meant to learn from past interactions — but it's a cost you should spend deliberately, not by default.
The Bottom Line
AI agent memory is what turns a clever-but-forgetful model into something that feels persistent and personal. The mechanics come down to a short-term context window, a long-term external store, and a retrieval loop that decides what to feed back in.
The frameworks — Letta, Mem0, Zep, LangMem — are all wrestling with the same hard questions: what to store, when to retrieve, and when to forget. None of them have fully solved staleness or privacy yet, and that's worth keeping in mind.
But the biggest lesson is the least glamorous one: memory is a tool, not a default. The best agents use it surgically, where it earns its cost — and skip it everywhere else. If you'd rather get those benefits without standing up the infrastructure yourself, that's exactly the kind of thing Pickaxe was built to handle.





