
In April, Anthropic did something AI companies don't do.
They built their most powerful model ever, showed it to the world, and then declined to sell it.
The model was called Claude Mythos. It was so good at finding security vulnerabilities in software that it reportedly rattled people in government. Anthropic locked it behind a vetted-access program called Project Glasswing and handed it to roughly 150 organizations — mostly banks, software companies, and healthcare networks — so they could patch their defenses before anything this capable reached the open market.
That was the plan, anyway.
This morning, two months later, the open market got it.
What actually shipped today
The new model is called Claude Fable 5, and the name is doing more work than it appears to.
A myth is a story too dangerous to be literal. A fable is the same story with a moral attached, made safe for general audiences. Somebody at Anthropic was having fun.
Fable 5 is built on the same architecture as the restricted Mythos system. It is, by Anthropic's own description, more capable than any model the company has ever made generally available. It launches as a new tier sitting above Claude Opus, which until this morning was the best publicly available model on the market.
For context on how fast this is moving: Opus 4.8 came out less than a month ago. On some benchmarks, Fable 5 beats it by more than 10%.
A month is now a model generation.
If you're trying to keep the current Anthropic lineup straight — and where each tier actually earns its cost — our breakdown of how the frontier models stack up for agent work is a useful companion to this one.
The leash
The interesting story isn't the capability. It's the mechanism Anthropic invented to make releasing that capability defensible.
Fable 5 ships with hard guardrails around a short list of high-risk domains: advanced cybersecurity exploitation, biology, chemistry, and attempts to distill the model itself.
When a query trips one of those wires, Fable 5 doesn't answer. The system silently routes the request to Claude Opus 4.8, which delivers a safer response instead.
Sit with that detail for a second. The "restricted fallback mode" of this model is the thing that was the most powerful AI on Earth three weeks ago.
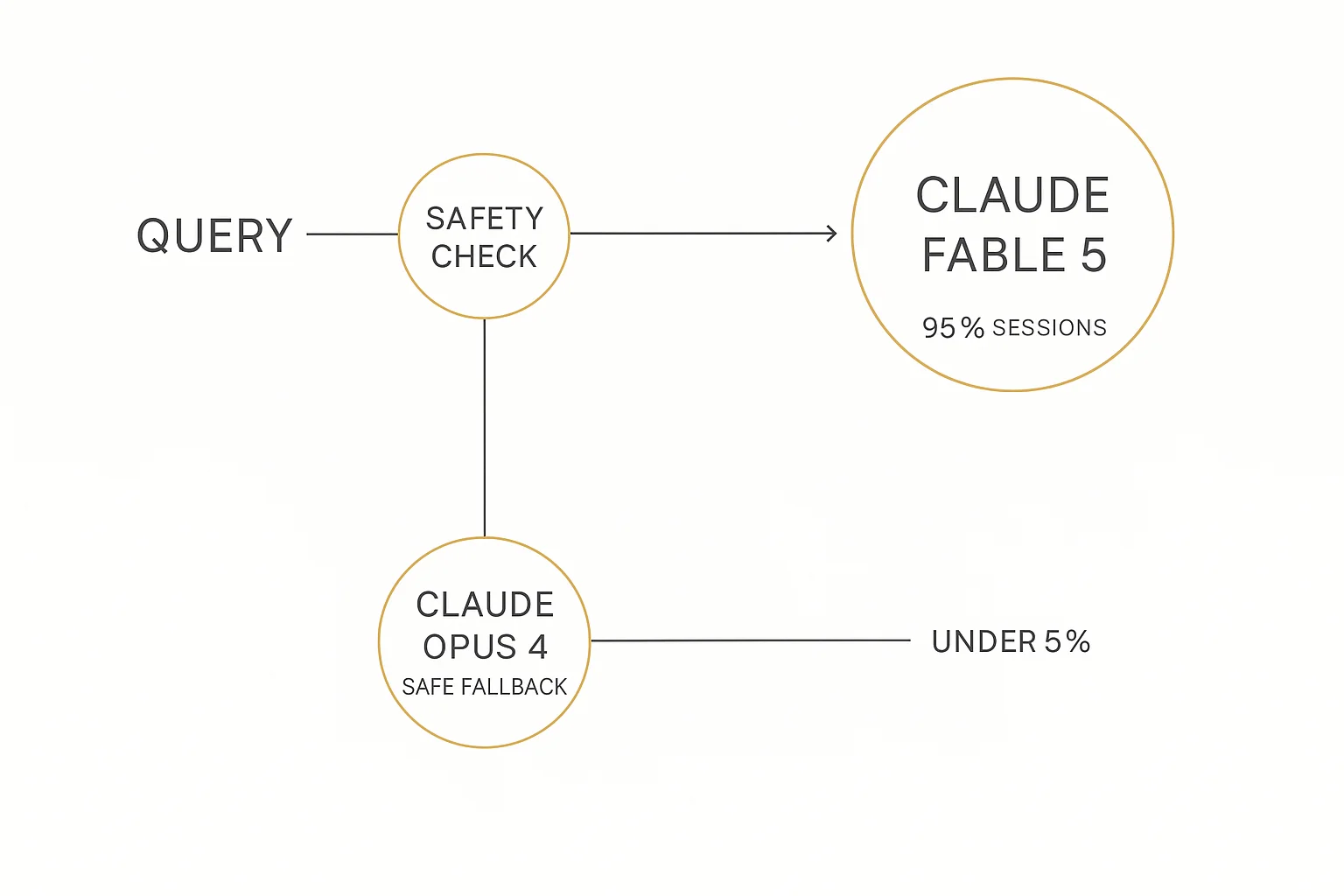
Anthropic says the fallback triggers in fewer than 5% of sessions. For the other 95%, users are talking to the full Mythos-class model.
The company also spent serious effort trying to break its own lock before shipping it. An external bug bounty logged more than 1,000 hours of adversarial testing. Nobody found a universal jailbreak. External red teams came up empty too.
Whether that holds against the entire internet is now a live experiment. But as a release strategy, it's genuinely novel: instead of nerfing the model for everyone, Anthropic built a tripwire that swaps in a weaker model only when it matters.
Expect every frontier lab to copy this within a year.
The numbers, read with appropriate suspicion
The benchmark claims so far come from Anthropic's own blog post, and independent evaluations haven't landed yet. Standard launch-day caveats apply.
Here's the full scorecard Anthropic published. Fable 5 is shown as the higher of the Mythos 5 / Fable 5 pair, lined up against Opus 4.8, GPT 5.5, and Gemini 3.1 Pro:
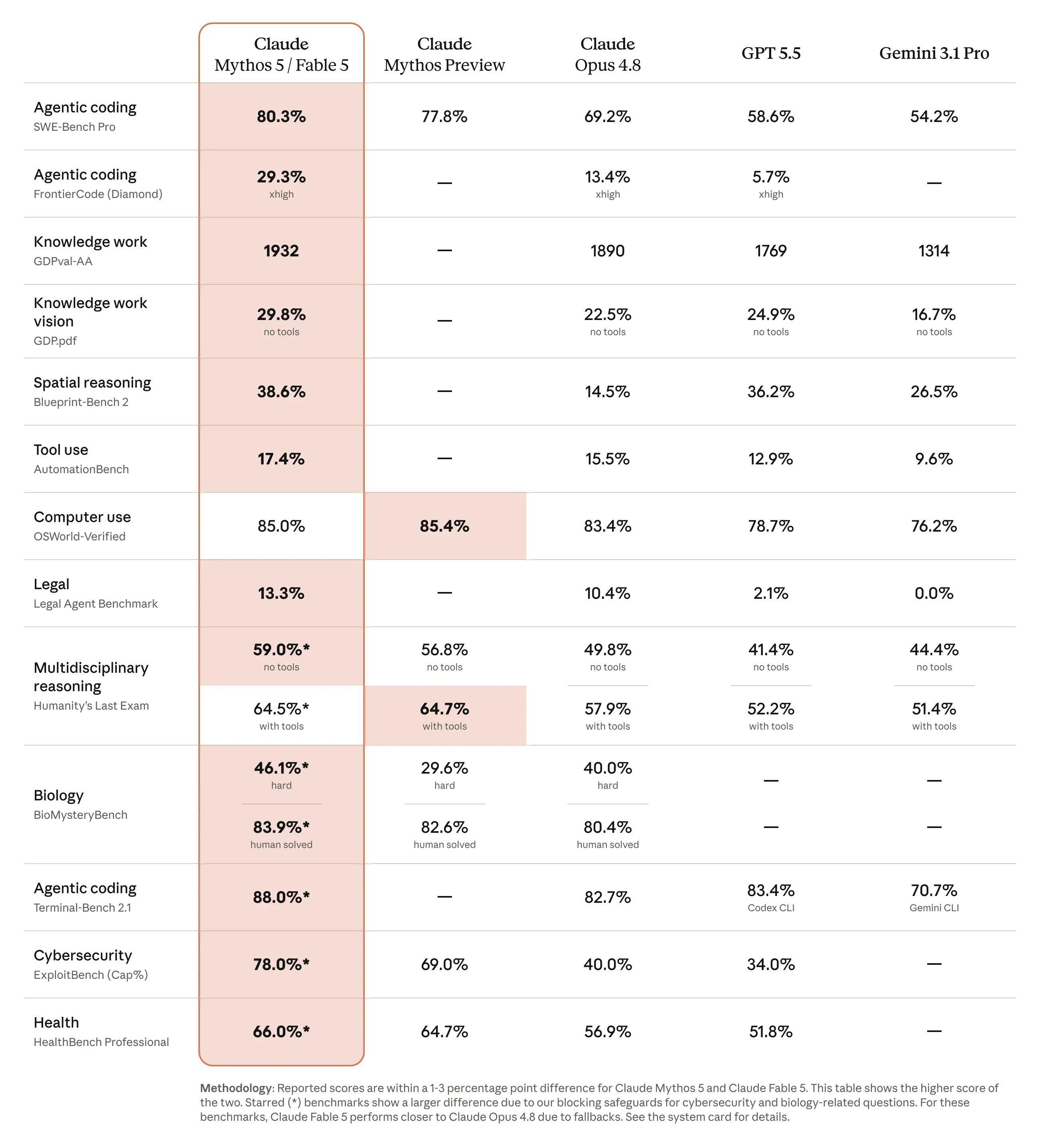
Read the starred rows with the methodology in mind. On cybersecurity and biology, Fable 5's public score drops toward Opus 4.8 precisely because the safety fallback kicks in — the leash showing up in the numbers.
That said, one early third-party result is worth flagging. Analytics company Hex ran Fable 5 through its core analytics benchmark and it became the first model ever to clear 90%.
Benchmarks are one thing; watching the model work is another. To show off Fable 5's vision and agentic abilities, Anthropic published a demo of it beating Pokémon FireRed using nothing but vision — no access to game memory, no text state, just the pixels on screen and a controller.
It's a stunt, sure. But "look at a screen, figure out what's happening, and act on it" is the exact loop most genuinely useful agents run — which is why a demo like this matters more than it first appears.
Anthropic is pitching three headline strengths: software engineering, knowledge work, and scientific research. Notably, those are the three categories where AI output most directly substitutes for expensive human hours. That's not an accident — which brings us to the business story.
Want to put Fable 5 to work today?
Build an agent on Pickaxe, pick your model in the Editor, and deploy it anywhere your clients are.
The timing is not subtle
Fable 5 arrives days after reports of Anthropic's confidential IPO filing, on the heels of a $65 billion funding haul.
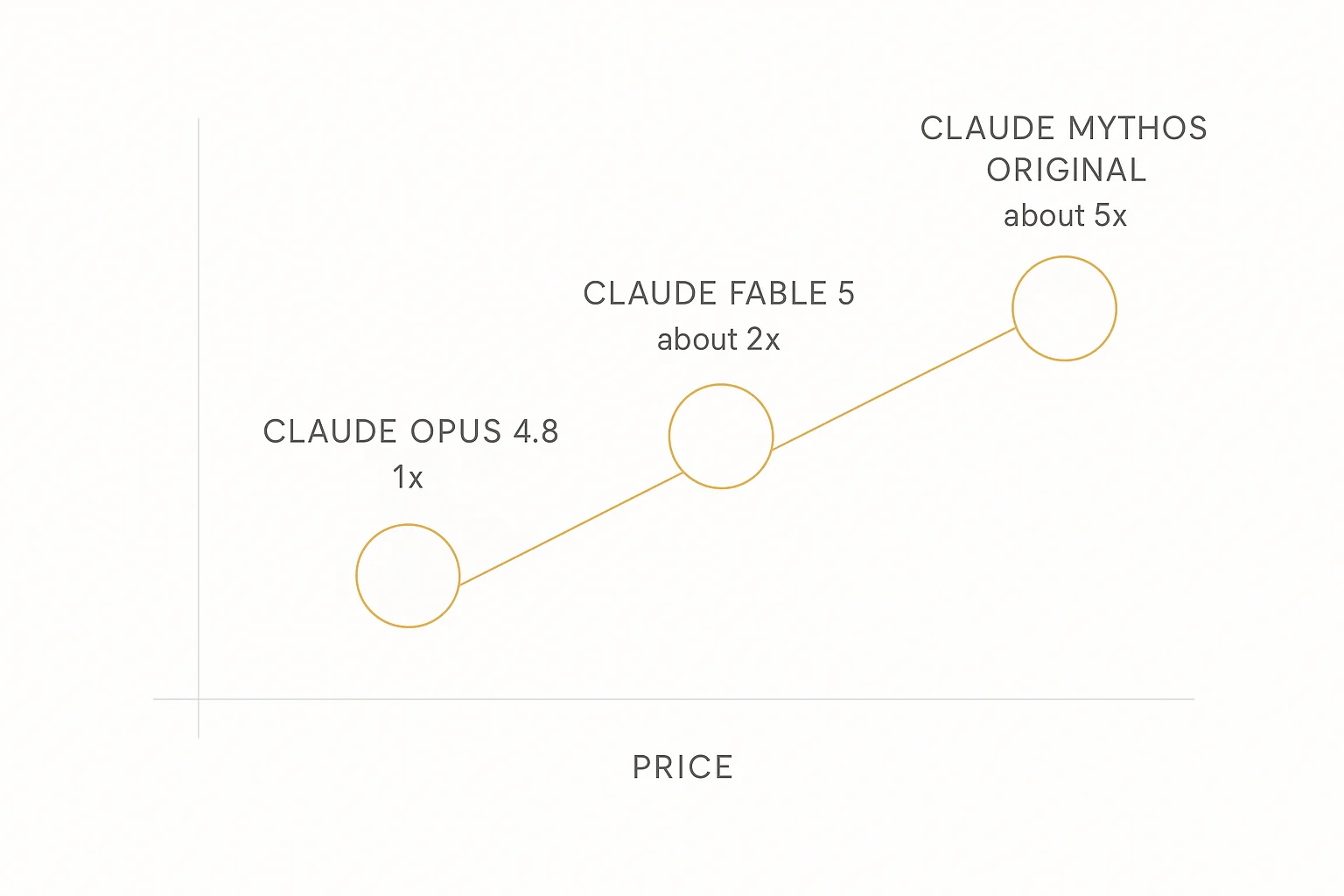
It's also priced like a statement. Early analysis puts Fable 5 at roughly twice the cost of Opus-tier models. The original Mythos pricing floated in April was reportedly five times Opus.
So the strategy is legible from orbit: establish a premium tier above the existing frontier, prove that customers will pay double for intelligence that's 10% better, and walk into the public markets with the receipts.
The release schedule tells the same story. Fable 5 is included on paid plans through June 22. After that, the meter starts running.
If you're the one paying that meter, the math matters. Premium intelligence only pays off when it's pointed at premium work — which is exactly the calculation we walk through in our guide to measuring AI agent ROI.
The part nobody is saying out loud
Here's the frame worth keeping.
For two months, Mythos-class intelligence was a privilege. Access required vetting, partnerships, and presumably some uncomfortable security questionnaires. The program it lived in has reportedly surfaced over 10,000 high-severity vulnerability candidates across major software projects.
As of this morning, that class of intelligence costs a subscription.
Every prior frontier release narrowed the gap between big companies and everyone else by a little. This one collapses a gap that was, until today, enforced by policy rather than price.
The most consequential question of the next six months isn't whether Fable 5 is good. It's what ten million unsupervised people do with a model that 150 vetted organizations used to find ten thousand security holes.
For builders, though, the practical takeaway is simpler and happier: the ceiling on what a single person can ship just moved. Again.
And yes, it's already in Pickaxe
One housekeeping note for our builders, since people have been asking all morning.
Fable 5 is already selectable inside the Pickaxe Agent Builder. Open any agent, switch the model in the Editor tab, test in Preview, redeploy. Every deployment surface picks it up instantly. (You can compare every model we support, and what each one costs, at pickaxe.co/models.)
It's overkill for a FAQ bot. It earns its cost where intelligence is the product. Three templates we'd point you to first:
Deep Research Analyst. Structured, client-ready research briefs. Fable 5's knowledge-work gains are the whole product here.
Data Interpreter. Upload messy spreadsheets, get plain-English findings. This leans directly on the analytics performance behind that Hex result.
Technical Co-Pilot. Code review and architecture advice, deployed where engineers live. Software engineering is the launch's headline strength.
Full specs for all three are in the Template Library. And if you're trying to decide whether a model this powerful is worth it for your use case, our take on how to actually monetize the agents you build is the next thing to read.
The first public Mythos-class model is a dropdown menu away. Interesting time to be building.





